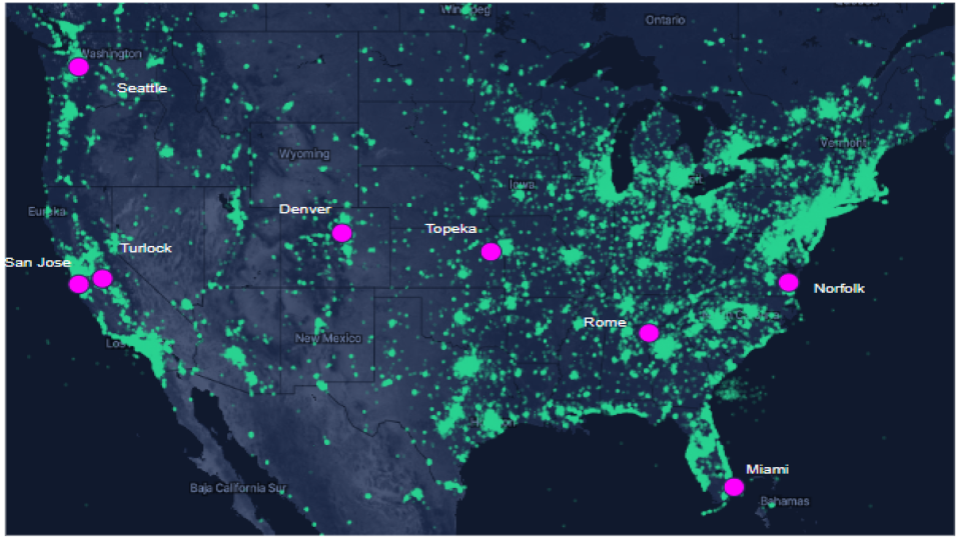
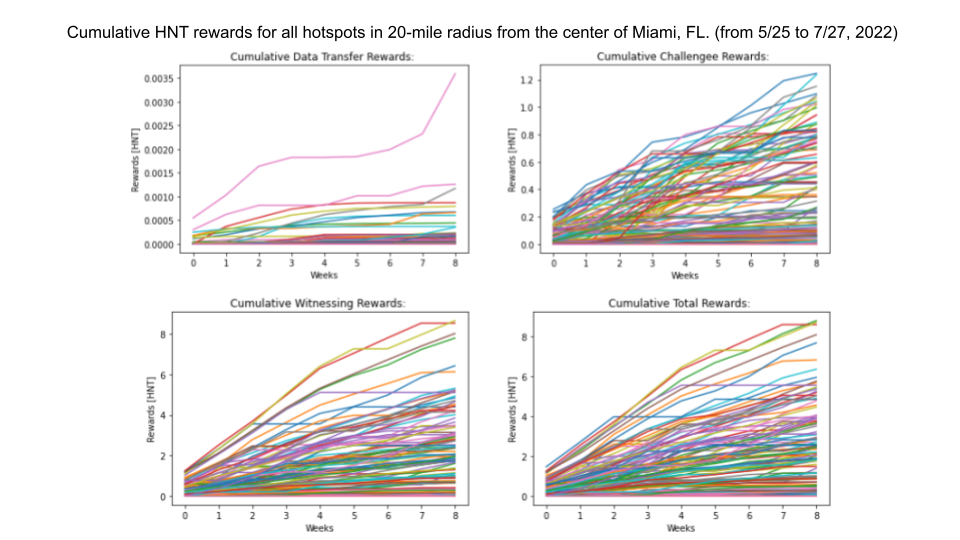
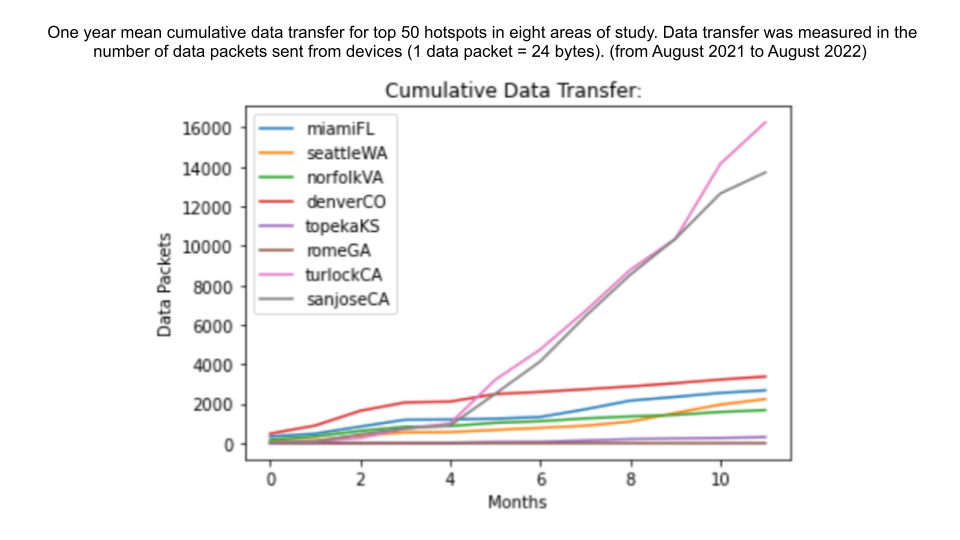
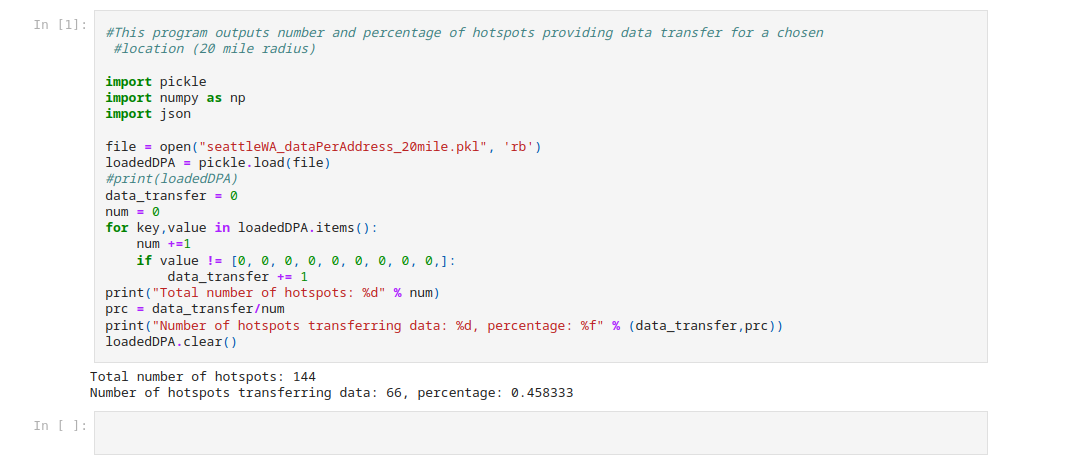
Note: to see the source code and Python scripts written for this project, environment setup guidelines, and read a more detailed story about the project, consult the README file in the project's GitHub Repository
Big Data mining and in-depth research on economic demand and network traffic of the Helium Network, a distributed and decentralized Internet of Things (IoT) network, which runs on a digital ledger of transactions called the Blockchain, with native cryptocurrency abbreviated as "HNT". Since Helium Blockchain is a public blockchain, data on all past transactions on the network is visible to the public
This research uses Python scripts with HTTP requests to Helium Blockchain API to access the Blockchain's database and collect data on network traffic and HNT cryptocurrency data mining statistics, to study Helium network's dynamics, economic supply and demand
Programming environment chosen for this project was Anaconda with Jupyter Notebook, while Python was selected as the most suitable language
Requests Python library was used to send HTTP requests to fetch data from the blockchain, Matplotlib library was used to represent the data in either numerical tables or visually as graphs, Numpy library helped with its tools for array manipulation, JSON was used to store data in a readable form, Time and Datetime libraries were utilized to work with time parameters, and finally Pickle was used for converting output objects into byte streams, stored in .pkl files for further analysis
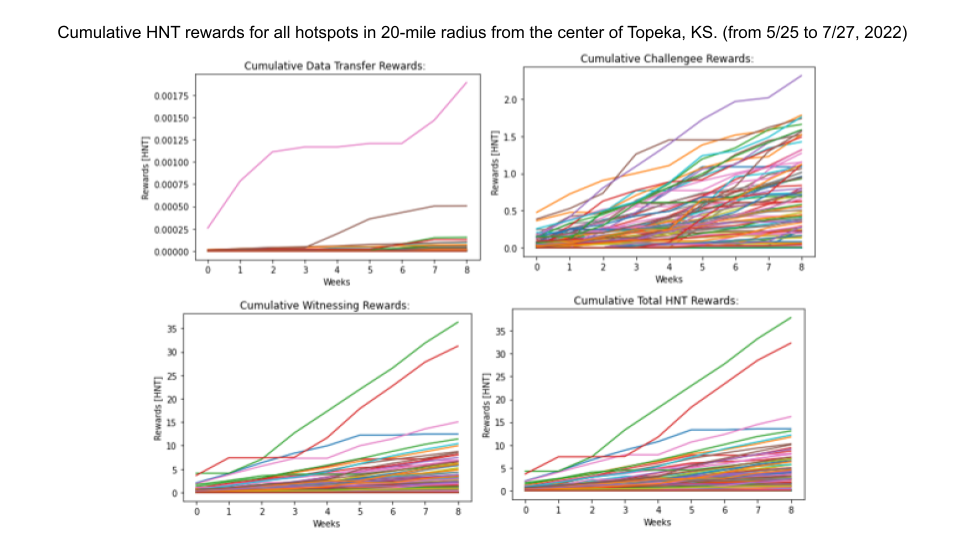
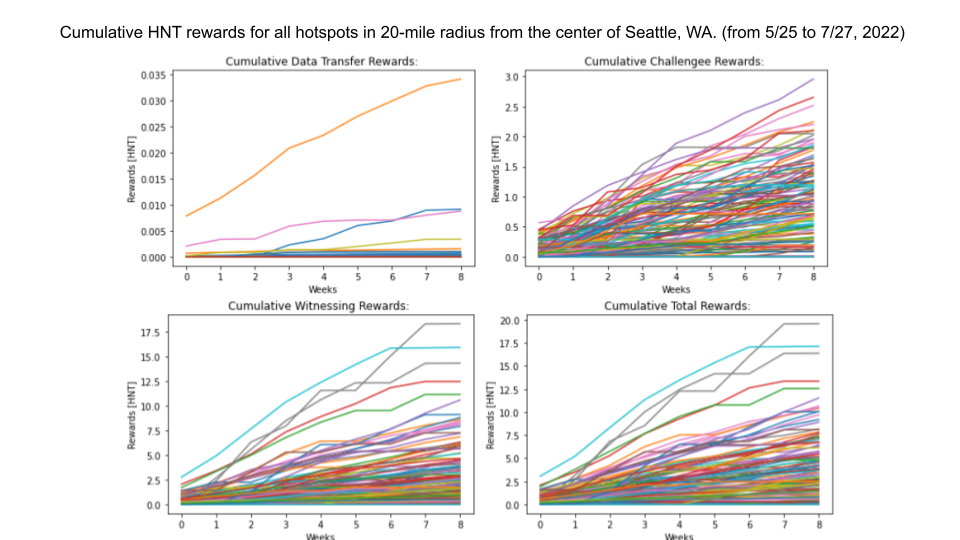
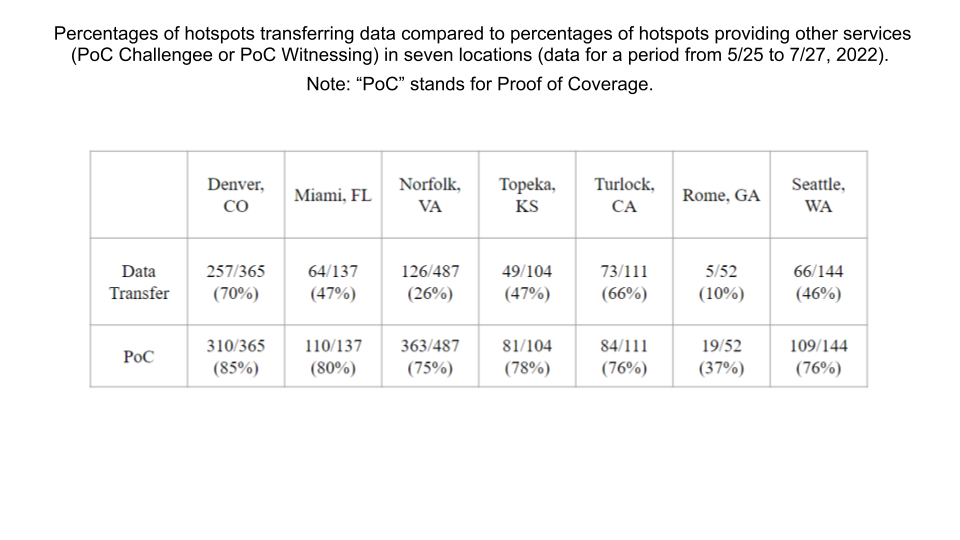
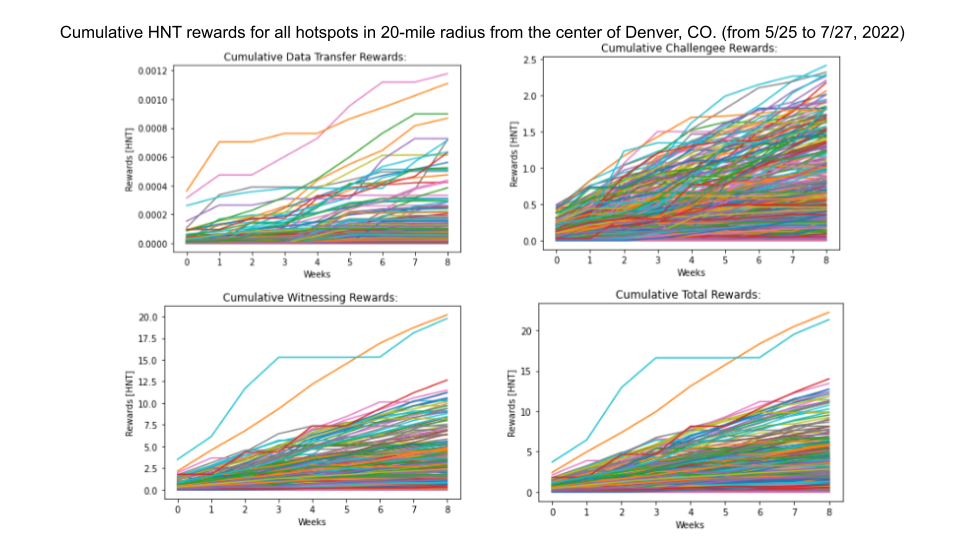
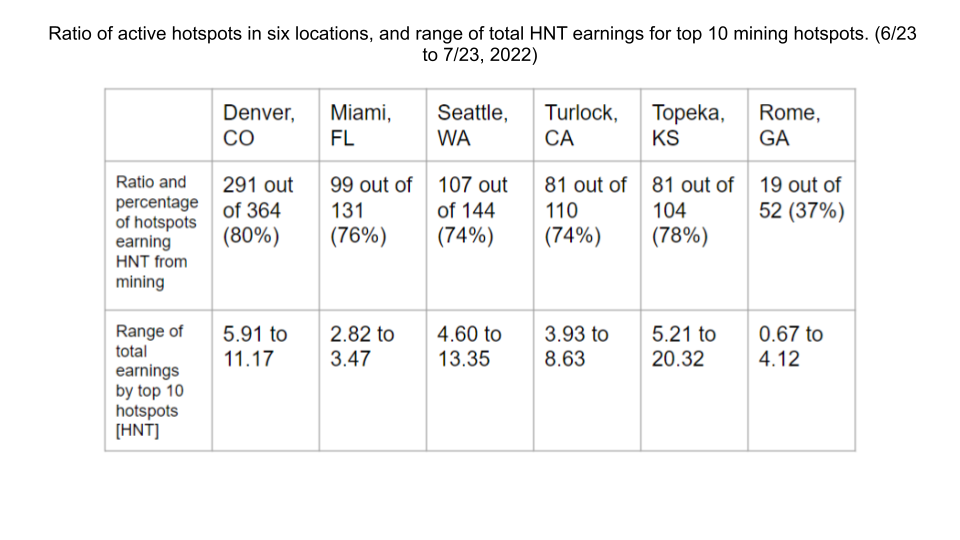
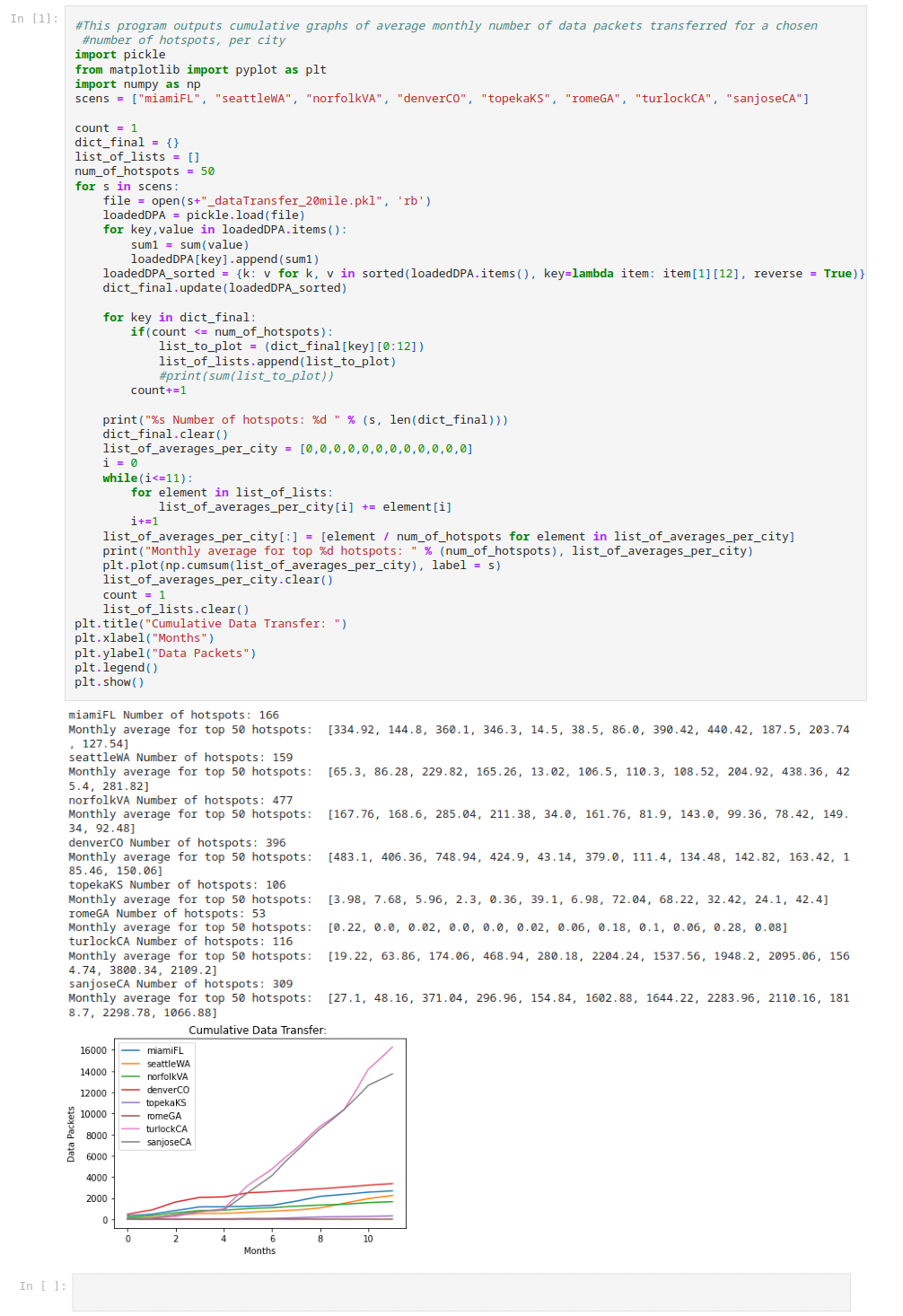
The demand for the Helium network's coverage was analyzed by observing two relevant variables: HNT rewards to hotspots for various network services, and overall data traffic on the network
A significant problem that appeared during the project were computational limits of the personal machine I used at that time to fetch, store, and process all the data I needed to perform my study. Some scripts took entire nights to finish since data for 8 cities over a period of up to 1 year had to be analyzed, and each city's total network transaction data would sometimes take hours to be fully processed. I ended up getting help from my mentor who used another machine (which had more RAM capacity and faster CPU) and fetched the data I needed, stored it as .pkl files, and sent them to me for further analysis
Another obstacle I experienced in the beginning of this research was having to understand how to use cursor logic within my scripts for sending consecutive HTTP requests to fetch serialized data that came from weeks, sometimes months of transactions between hotspots on the network. This was the only way to fetch all data for entire time intervals that were studied
I set on a course of this project to gain research experience related to my discipline, and learn more about big data and how data analysis can be performed with the help of programming languages
From this project I learned what things like Blockchain, Internet of Things, Decentralized Networks, Hotspots, Cryptocurrency Mining and other such terms mean and how they relate to what I already know about existing Internet technologies and digital networks
By conducting this research I got a lot of experience programming in Python, and using its libraries for connecting to external APIs, and to perform data collection, processing, representation, and visualization
And finally this internship taught me how to write scientific papers, perform scientific inquiry by using digital tools, interpret data collected with observed variables in mind, and draw conclusions about the topic under study